
An AI model recently achieved 93 percent accuracy in recovering keystrokes over Zoom, and 95 percent accuracy from a smartphone microphone placed nearby. This is not a theoretical proof-of-concept. It is documented in peer-reviewed research and verified in coverage by IEEE Spectrum and Ars Technica. These results reveal an alarming new chapter in cyber-espionage, where AI acoustic side-channel attacks transform ordinary sounds into stolen secrets.
At their core, AI acoustic side-channel attacks exploit the subtle, often imperceptible sounds emitted by keyboards, devices, and other hardware. They take what was once considered harmless background noise and process it with machine learning models capable of mapping those sounds to precise keystrokes or commands. For professionals, policymakers, and security-conscious technologists, this represents a paradigm shift. The barrier to execution is no longer specialized hardware or months of manual analysis. Today, a laptop’s microphone or a phone’s motion sensor can be enough to launch an effective attack.
This leap in capability is not just about better software. It is about a convergence of trends: the ubiquity of high-quality microphones in everyday devices, the rapid improvement of AI models in recognizing complex patterns, and the expanded attack surface of remote and hybrid work. The same tools that make voice assistants responsive and virtual meetings seamless can be turned into covert surveillance systems. In some cases, an app hears passwords via AI without ever explicitly announcing its microphone use, taking advantage of permission gaps and user complacency.
In this article, we will break down what AI acoustic side-channel attacks are, how they work, and why they are uniquely dangerous in today’s environment. We will examine verified real-world cases, from Zoom-based keystroke recovery to ultrasonic command injection into voice assistants. We will explain why these threats remain underestimated even within the security community, and we will outline practical, evidence-based strategies for mitigation.
You will also see how this threat fits into the broader landscape of AI-driven risks, which we have explored in depth in our earlier coverage of Shocking AI-Powered Cybersecurity Threats in 2025: Protect Yourself Against New Advanced Attacks. The goal is to equip you with the knowledge to recognize and counteract one of the most technically sophisticated and operationally stealthy threats emerging today.
Understanding the mechanics is the first step toward defense. Let’s start by examining what these attacks are, how they differ from traditional side-channel exploits, and why AI changes the stakes entirely.
What Are AI Acoustic Side Channel Attacks?
Core Definition and Mechanism
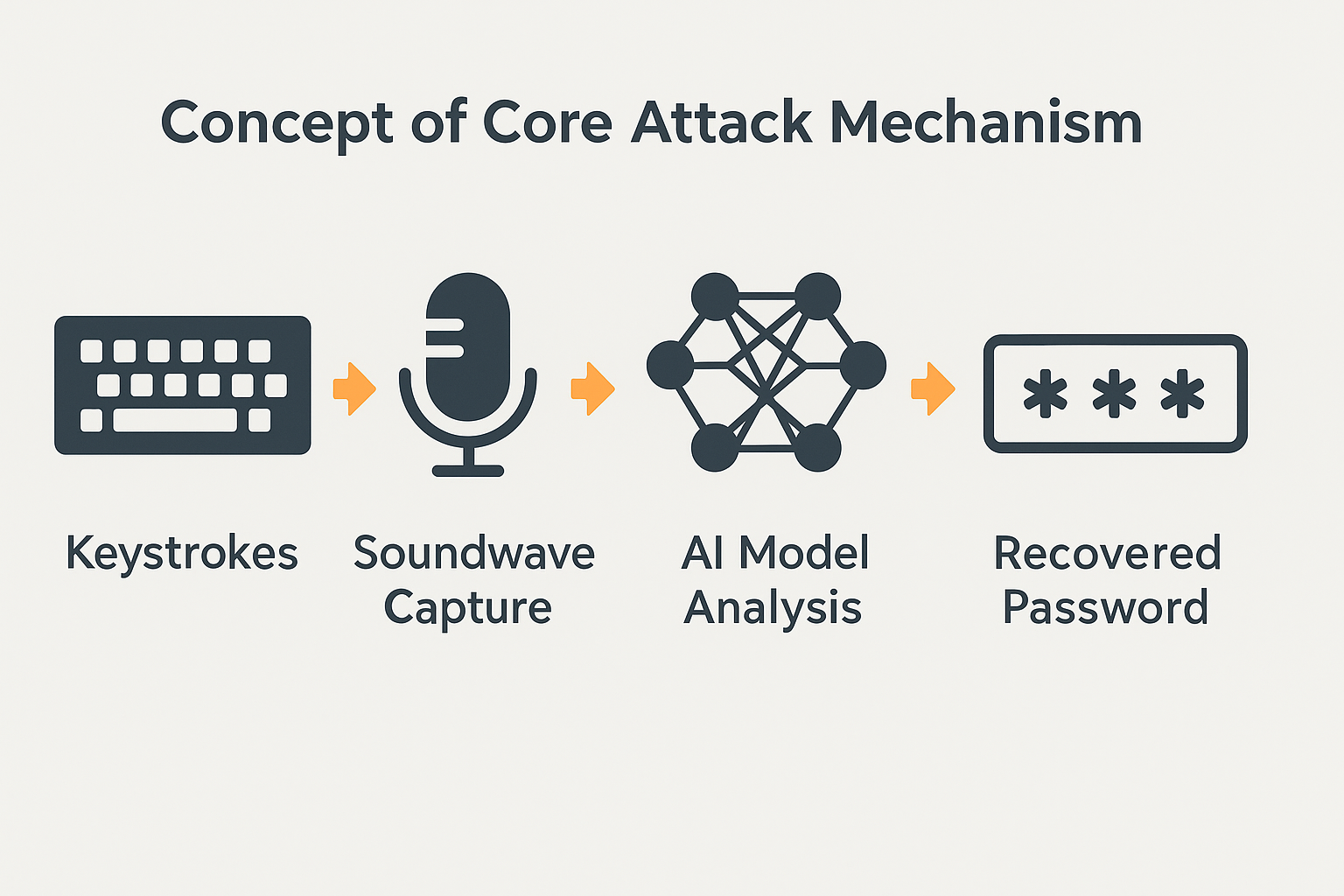
An acoustic side-channel attack occurs when an attacker captures and analyzes sound emissions from a device to extract sensitive information. Every keystroke on a keyboard produces a unique acoustic signature, shaped by the key’s position, the device’s materials, and the typing style. In traditional side-channel research, these signatures were analyzed manually or with basic statistical tools, often requiring specialized recording equipment and controlled conditions.
With AI acoustic side-channel attacks, machine learning models are trained on labeled audio samples to classify each keystroke sound with high precision. A recent IEEE Spectrum report highlights how these models can infer passwords and other sensitive text with alarming accuracy, even in noisy environments. Instead of spending weeks analyzing waveforms, an attacker can automate the process, enabling rapid extraction of large volumes of data.
Why AI Amplifies the Risk
Before AI, acoustic side-channel attacks were limited in scope and practicality. They required consistent conditions, high-end microphones, and expert analysis. Deep learning changed that. Modern neural networks can adapt to different hardware, account for variations in typing, and improve with additional training data. New research incorporating transformer architectures and large language models suggests that accuracy rates could climb even higher while reducing the need for prior knowledge about the target system.
AI also scales. Once trained, a model can process thousands of recordings quickly, turning a labor-intensive niche attack into something that could be deployed broadly. This scalability raises the threat from isolated espionage incidents to a potential systemic security risk.
Types of Data Vulnerable to Acoustic Capture
While most demonstrations focus on keystrokes, the scope is broader. Any consistent sound pattern linked to an input or command can be exploited. Passwords are an obvious target, but so are credit card numbers, personal messages, or proprietary code typed during development sessions. Some attacks do not even require microphone access. The EarSpy project demonstrated that motion sensors could pick up vibrations from ear speakers, allowing attackers to infer speech content and speaker identity without direct audio capture. SurfingAttack showed how ultrasonic signals transmitted through a tabletop could inject commands into voice assistants, bypassing user interaction entirely.
This range of vulnerabilities underscores that AI listening attacks on passwords are just one piece of the puzzle. The same principles can be applied to broader categories of sound based side-channel security threats, creating challenges that span personal, corporate, and national security domains.
Emerging risks like AI acoustic side-channel attacks show how quickly threats evolve beyond traditional malware or phishing. Get ahead of these developments. Join the Quantum Cyber AI Brief now for weekly insights on AI-driven threats, deepfake scams, and global cyber shifts before they hit headlines.
How Can Apps Actually Hear Your Password?
Microphone Access Permissions and Platform Controls
Modern mobile and desktop operating systems include privacy frameworks designed to control when an app can access the microphone. On iOS, the App Privacy Report logs how often each app uses sensitive permissions, including microphone and sensor access. Users can review this log to see if an app has recorded audio unexpectedly. Similarly, Android offers a Privacy Dashboard that shows a timeline of microphone, camera, and location access across all apps. From this dashboard, users can revoke permissions instantly.
These controls are meant to ensure that no app hears passwords via AI without explicit consent. Apple also requires user permission for mic access, with an on-screen indicator when it is active. However, the existence of these systems does not eliminate the risk entirely, especially when permissions are granted broadly and left unchecked.
Persistent Risks Despite Permission Controls
Research shows that permission frameworks do not always prevent misuse. A 2025 investigation by Hexiosec and Which? analyzed 20 of the UK’s most popular apps and found that 14 requested microphone access. Across these apps, there were 882 total permission requests, many flagged as high-risk. An acoustic side-channel password attack becomes easier if the attacker already has a persistent audio feed from a compromised or overly permissive app.
Permissions are often granted at installation and rarely revisited. This allows background or opportunistic recording to occur for extended periods. If the app is compromised, malicious code can use AI listening attacks on passwords to capture login credentials, credit card data, or other sensitive keystrokes.
Stealth Factors and User Awareness Gaps
Even with on-screen indicators, most users are not actively watching for microphone activity. People tend to trust familiar apps and may overlook permission creep, where new app updates add capabilities that are not necessary for its core function. This trust gap is precisely where attackers can operate. By embedding AI-driven capture into legitimate-seeming processes, a malicious actor can blend into normal device behavior.
The danger is compounded when apps collect sensor data beyond audio. Motion sensors, as demonstrated in EarSpy, can bypass microphone permission entirely and still extract private information. This means sound based side-channel security is not solely a matter of microphone control, but also of securing all data sources that can carry acoustic or vibration patterns.
If attackers can gain audio or sensor access, the next question is how they can use it in practice. The reality becomes clearer when we examine real-world incidents and research that demonstrate just how precise and damaging these attacks can be.
5 Shocking Examples of Acoustic Side Channel Attacks
High-Accuracy Keystroke Recovery via Zoom and Smartphones
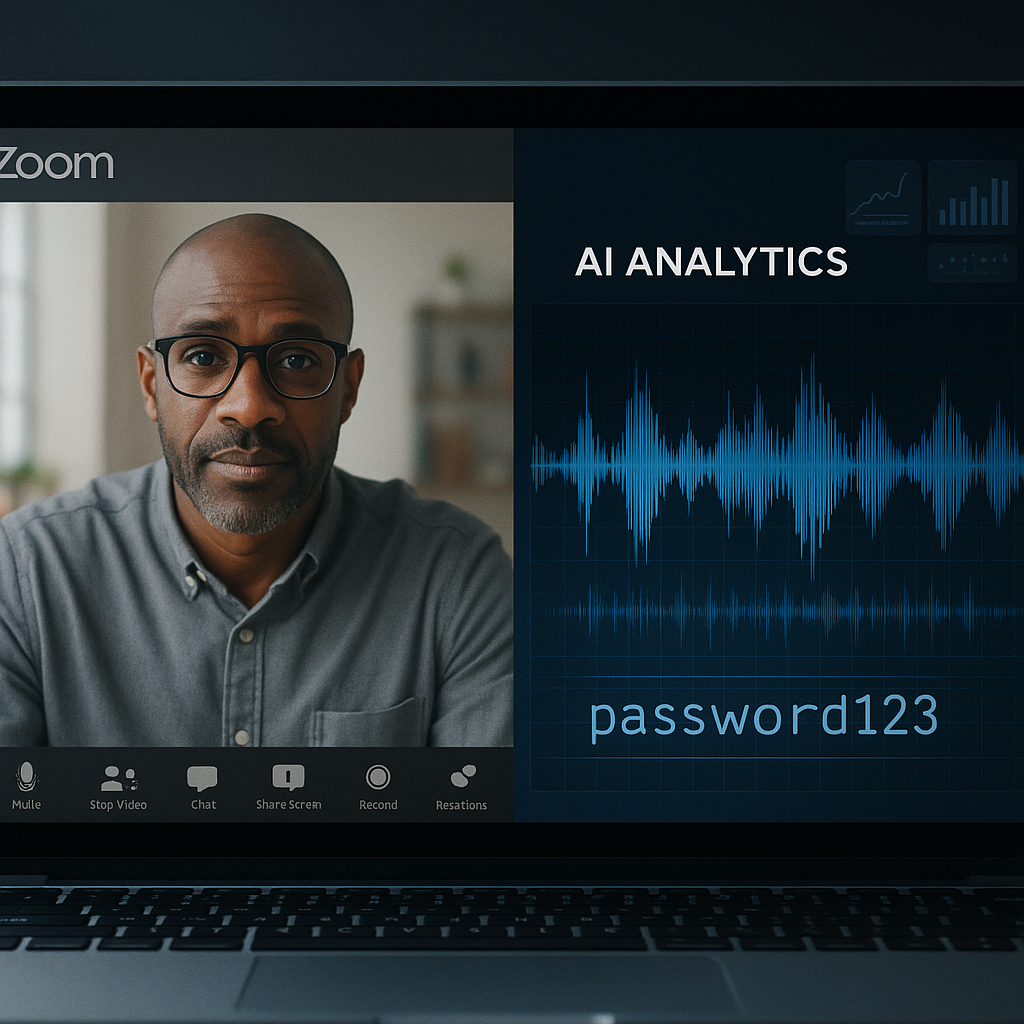
In 2023, researchers demonstrated that AI acoustic side-channel attacks could recover keystrokes with startling precision. Using a nearby smartphone microphone, their model achieved 95 percent accuracy. Over a Zoom call, it still reached 93 percent accuracy in classifying keystrokes. These results were validated and widely reported by IEEE Spectrum and ArsTechnica. For a professional on a confidential call, this means an attacker could, in real time, reconstruct passwords or sensitive messages typed during the meeting.
Robustness in Realistic Environments
A 2024 follow-up study tested whether such attacks could succeed under more realistic, less controlled conditions. The researchers introduced background noise, varied typing styles, and different hardware. Even then, the model maintained an average accuracy of 43 percent across test cases. While lower than lab conditions, this still represents a serious risk. In many cases, attackers only need partial recovery to guess passwords or piece together sensitive information.
EarSpy – Microphone-Free Eavesdropping

The EarSpy project revealed that attackers do not always need microphone access for an AI listening attack on passwords or speech. By using motion sensors to detect vibrations from a phone’s ear speaker, researchers could infer both the content of a call and the speaker’s identity. This was done without triggering microphone permission alerts, making it stealthy and difficult for users to detect.
SurfingAttack – Inaudible Command Injection

SurfingAttack showed another dimension of sound based side-channel security risks. Using ultrasonic guided waves transmitted through a tabletop, researchers could send inaudible commands to a voice assistant. This enabled actions like sending messages or making calls without user interaction, all while leaving the victim unaware. The attack works because ultrasonic frequencies can be picked up by voice assistant microphones but are outside the range of human hearing.
These examples confirm that AI acoustic side-channel attacks are not confined to controlled lab demos. They are adaptable, work in varied conditions, and can exploit multiple input vectors. The real concern for professionals and policymakers is not just the technical novelty, but the ease with which these methods could be integrated into broader cyber-espionage campaigns.
The technical sophistication of these attacks is only part of the picture. Their true danger lies in how stealthy and underestimated they remain across industries. That is the focus of the next section.
Why These Attacks Are Dangerous and Surprising
High Accuracy and Real-World Feasibility
The precision demonstrated in AI acoustic side-channel attacks is not an academic curiosity. When a model can recover keystrokes with 90 percent or higher accuracy in common scenarios like video calls, it transforms the threat from theoretical to operational. Even partial accuracy, as shown in the 2024 study, can be enough to reconstruct shorter passwords or critical fragments of sensitive data. For an attacker, this means a practical and repeatable method of data exfiltration that requires no physical contact and minimal specialized equipment.
Expanding Attack Surface Across Devices
The most alarming factor is how many devices can serve as entry points. Laptops, smartphones, tablets, smart speakers, and even IoT appliances often contain microphones or sensors capable of detecting sound or vibration. This creates an environment where an acoustic side-channel password attack can be launched from virtually anywhere in a user’s technology ecosystem.
EarSpy and SurfingAttack highlight how diverse the vectors can be. EarSpy bypasses microphones entirely by exploiting motion sensors, while SurfingAttack uses ultrasonic signals to trigger voice assistants without a spoken command. This breadth complicates defensive strategies, because securing one category of device or input source does not eliminate the overall risk.
Underestimated Risk in Enterprise and Policy Settings
Despite the documented capabilities, many executives, policymakers, and CISOs still view these attacks as niche or unlikely. This underestimation is dangerous, especially in regulated industries where confidentiality is critical. A 2025 report from Hexiosec and Which? showed that microphone and sensor access remains widespread in popular apps, with 14 of 20 examined requesting microphone access and many permissions classified as risky. In environments where sensitive information is regularly handled, these permissions represent a latent vulnerability.
The subtlety of these attacks makes them harder to detect and prioritize. They do not rely on obvious malware signatures, and in some cases, they leave no log entries that would alert security teams. Combined with the pace of AI advancement, this makes AI listening attacks on passwords and other inputs a growing concern that traditional security policies may not address adequately.
If the risks are misunderstood or ignored, defenses will lag far behind offensive capabilities. The next logical step is to look at what can be done now, at both an individual and organizational level, to reduce exposure to sound based side-channel security threats.
How to Protect Yourself Against AI Acoustic Eavesdropping

Behavioral Changes for Individuals
Reducing the risk of an AI acoustic side-channel attack begins with altering daily habits. Avoid typing passwords or sensitive data during video calls or when you know your device’s microphone is active. This prevents attackers from pairing sound signatures with visible context. Use two-factor authentication and a password manager to limit the usefulness of any single captured credential. Even if an attacker manages to conduct an acoustic side-channel password attack successfully, additional authentication steps can stop them from gaining access.
Technical Countermeasures
There are practical steps that reduce the attack surface at the technical level. Use mic blockers or hardware switches where available to ensure the microphone is physically disconnected when not in use. For meetings where sensitive input might be typed, consider generating white noise to interfere with AI listening attacks on passwords. On both iOS and Android, review microphone permissions regularly. The Android Privacy Dashboard, and iOS App Privacy Report allow you to see which apps are using your microphone and how often. Disable access for apps that do not need it. For iPhone users, the “Control access to the microphone” setting makes it easy to turn off mic access entirely for specific apps.
Organizational Policies and Training
At the enterprise level, mic access should be treated as a security-relevant permission, not just a user preference. Security teams should maintain an approved apps list that limits which applications can use microphones or motion sensors. Cybersecurity training should include modules on sound based side-channel security threats, helping employees recognize when and where to avoid typing sensitive data.
Incident response playbooks should anticipate scenarios where audio or sensor data has been compromised. This ensures that containment and remediation steps are not delayed by uncertainty.
For more comprehensive strategies, see our guide on How to Secure Your Smart Home from Hackers: The Ultimate Guide 2025, which explores how to harden both personal and corporate devices against AI-driven exploits.
Defensive action is only part of the equation. To prepare for what’s next, we need to understand how this attack class is likely to evolve as AI models and hardware capabilities advance.
Future Trends and What Security Experts Should Watch
Advances in AI Models for Side Channels
AI acoustic side-channel attacks are improving as researchers apply transformer architectures and large language models to classify keystrokes more reliably across different keyboards and environments. A recent study reports gains from vision transformers and LLMs that reduce dependence on tightly controlled lab conditions, which means models can adapt faster to new acoustic profiles and still infer input with strong accuracy.
This is directly relevant to an acoustic side-channel password attack during remote work. It also suggests a coming wave of tools that automate feature extraction, calibration, and error correction, which would lower the barrier for adversaries. As these techniques mature, AI listening attack on passwords workflows will demand fewer samples for fine-tuning, and attacks may generalize across device classes with less prior knowledge.
Another shift is the integration of multi-modal sensing. Future pipelines may combine audio, vibration, and limited visual context from screen reflections or conferencing videos to amplify classification confidence. This would extend sound based side-channel security risks into hybrid attacks that fuse signals from microphones, motion sensors, and even smart speaker telemetry, making it harder to defend a single vector in isolation. The net effect is a move from point solutions to scalable attack frameworks that can be reused across organizations and platforms.
Potential Policy and Regulatory Developments
Policy responses will need to evolve as AI acoustic side-channel attacks gain mainstream visibility. Mobile platforms already require runtime mic permissions and show indicators, yet studies continue to find extensive and often unnecessary sensor access across popular apps, including requests for microphones that create latent risk if abused. Expect calls for stricter app store vetting, tighter justifications for sensitive permissions, and more granular background access controls. For regulated sectors, security leaders should anticipate guidance that treats acoustic capture vectors on par with other side channels. Internal audit programs can begin by aligning mic and sensor inventory with least-privilege policies and by documenting when an app hears passwords via AI as part of a modeled threat scenario.
There is also momentum in broader offensive AI discourse. Security literature is pushing for standards that address both adversarial and offensive AI, which would include acoustic side channels among other machine-driven intrusion methods. This points to emerging frameworks that align risk assessment, model governance, and incident disclosure for AI-driven compromises. Policymakers should consider cross-functional tasking that links consumer protection, platform governance, and critical infrastructure guidance, because acoustic attacks intersect all three domains.
Similar to the hidden risks outlined in our analysis of Google’s AGI safety blueprint, policymakers will need to anticipate covert AI-driven vulnerabilities in acoustic channels as part of broader governance strategies.
Defensive AI Research
Defenders are not standing still. Research groups are experimenting with adversarial noise shaping that degrades classification performance of AI listening attack on passwords while remaining minimally disruptive to human conversation. There is growing interest in on-device classifiers that detect suspicious acoustic capture patterns or ultrasonic command signatures similar to those used in SurfingAttack, with automated responses such as dynamic noise injection or temporary mic gating during high-risk events. Organizations should pilot monitoring that correlates mic usage spikes with sensitive workflows such as admin logins or financial approvals, then enforce conditional access if anomalies are detected. These measures complement traditional controls by directly targeting sound based side-channel security risks at the signal and model layers.
Open benchmarks are also needed. Shared evaluation suites for cross-device recordings, varied room acoustics, and keyboard types would let defenders test countermeasures against standardized datasets. This would help security teams validate that an acoustic side-channel password attack is effectively disrupted by a given mitigation, not just theoretically addressed. As vendors add more sensors, defenders should assume multi-signal fusion and build layered controls that can blunt several inputs at once.
Taken together, these trends signal a maturing threat category that will spread as tools and knowledge circulate.
Defensive action must begin now, but staying informed matters just as much. Hackers move fast. Get weekly insights on AI-powered threats, policy shifts, and new vulnerabilities. Subscribe to our newsletter and stay one step ahead of tomorrow’s attacks.
Conclusion
AI acoustic side-channel attacks are no longer fringe security research topics. They have moved into the realm of practical, repeatable, and scalable cyber threats. Peer-reviewed studies have shown that an acoustic side-channel password attack can achieve over 90 percent accuracy in controlled environments, and even in real-world conditions, attackers can extract meaningful portions of sensitive input. Techniques like EarSpy and SurfingAttack prove that sound based side-channel security risks extend beyond microphones, exploiting vibration sensors and ultrasonic signals to capture or inject commands without a user’s awareness.
For professionals and policymakers, the urgency is clear. The same hardware and AI capabilities that make communication tools, voice assistants, and collaborative platforms more productive also create stealthy channels for data leakage. In environments handling sensitive corporate, financial, or government information, an AI listening attack on passwords or other keystrokes should be treated with the same seriousness as network intrusion or credential phishing.
The defensive challenge is compounded by user behavior and policy gaps. Permissions for microphones and sensors are often granted broadly, left unchecked, and poorly understood. Even organizations with strict security protocols may overlook these vectors because they are harder to visualize than a phishing email or a firewall breach. Attackers exploit this underestimation, embedding their methods into seemingly benign software or using accessible sensor data to bypass expected protections.
Looking forward, the evolution of AI models will make these attacks more resilient, adaptive, and easier to deploy. Multi-modal fusion of audio, vibration, and visual cues will widen the attack surface further, requiring defense strategies that address not just one sensor type but the intersection of several. Regulatory and governance frameworks will need to adapt quickly, enforcing stricter control over app permissions and embedding acoustic threat modeling into compliance standards.
The time to act is now. Review and restrict app permissions, integrate acoustic side-channel awareness into security training, and explore both policy and technical safeguards. Hackers and espionage actors are already iterating on these techniques. Defensive measures must keep pace. By staying informed and proactive, individuals and organizations can blunt the effectiveness of these attacks before they become another routine tool in the cyber threat arsenal.
Key Takeaways
- AI acoustic side-channel attacks can reach over 90 percent accuracy in controlled settings and remain effective in real-world conditions.
- An acoustic side-channel password attack can be launched through common devices like laptops, smartphones, and even IoT hardware.
- AI listening attack on passwords techniques can bypass microphones entirely, as demonstrated by vibration-based and ultrasonic command injection exploits.
- Sound based side-channel security risks are underestimated in many enterprises and policy frameworks, leaving exploitable gaps.
- Defensive action should include stricter permission controls, user training, and exploration of adversarial noise or AI-based detection.
- Regulatory adaptation is essential to align consumer protection, platform governance, and critical infrastructure guidance.
FAQ
Q1: Can these attacks happen without my microphone being active?
Yes. Attacks like EarSpy can use motion sensors to detect vibrations from a device’s speaker, bypassing microphone access entirely.
Q2: Are encrypted messages safe from these attacks?
Encryption protects data in transit, but if an attacker captures keystrokes before encryption, such as through an AI listening attack on passwords, the content can be exposed.
Q3: Is this only a risk for high-profile targets?
No. While state-level actors may use these attacks for espionage, the scalability of AI models means they can target anyone, especially in environments with broad mic or sensor permissions.
Q4: Do noise-cancelling headphones protect against this?
Not necessarily. Noise cancellation is optimized for human hearing and may not block the frequency features AI models use to classify keystrokes or detect commands.